
https://minecraftathome.com/herobrine
Herobrine Seed Cracking attempt methodology
A summary of the methodology used by andrew_555 (Kminster) in a currently unsuccessful successful attempt at finding the world seed to the infamous image below.

I recognise that big tree, see you soon! (?)
Introduction
Given the coordinates, it is typically possible to find the world seed of any reasonable screenshot of a minecraft world using on the order of a day of computation time on a modern gpu (obviously preparing the data and program you are going to use may take much longer than this). Thus, what makes the find the seed of the Herobrine screenshot particularly difficult is the almost complete lack of coordinate information, due to the notable lack of any clouds being visible because of the tiny render distance which is in use.
The list of features in the image is fairly short:
Feature | Usefulness | Explanation |
Two big trees, both of size 11[1] | Crucial | The closer big tree probably has close to 48 bits of information on its own. Compared to terrain, big tree seeds can be tested significantly faster (although with more difficulty and less reliability, especially due to the leaf decay bug) |
Eight small trees | High | A big tree and a small tree cannot be in the same chunk, so we can eliminate all chunk offsets which put a big tree and a small tree in the same chunk. |
A hill, with “quads” visible | High | “Terrain anomalies” always occur at x/z coordinates which are both multiples of four. This reduces the number of possible chunk offsets from 256 to 16. Combining this with the requirement for big and small trees to be in separate chunks leaves only 8 chunk alignments. |
Dirt | High | The dirt texture tells us that the player is facing towards -X. |
Player has a pretty empty inventory | Medium | We guess that this means they have respawned recently. It seems reasonable to assume that the coordinates are within 512 blocks of (0,0). There are 4096 chunks within this distance of (0,0) |
Fog | ??? | It might be possible to use fog to see chunk borders, which would be great.[2] |
Chicken | None | Mob spawning is independent of world seed |
Herobrine | None | Herobrine was photoshopped into the screenshot, so has no relation to the world seed. |
Data used
This chart details virtually all the information used in this seed-cracking effort. It is in the form of a top-down view of the two big trees, giving the y coordinates of the highest leaf at each x/z coordinate. The origin used is the bottom trunk block of the closer big tree, t1. 4x4 “quads” found from terrain glitches are marked.
Small trees t3,t4,t5 are also marked as they cannot be in the same chunk as either big tree. They also may have blocked a failed big tree spawn attempt within two blocks of themselves.[3]
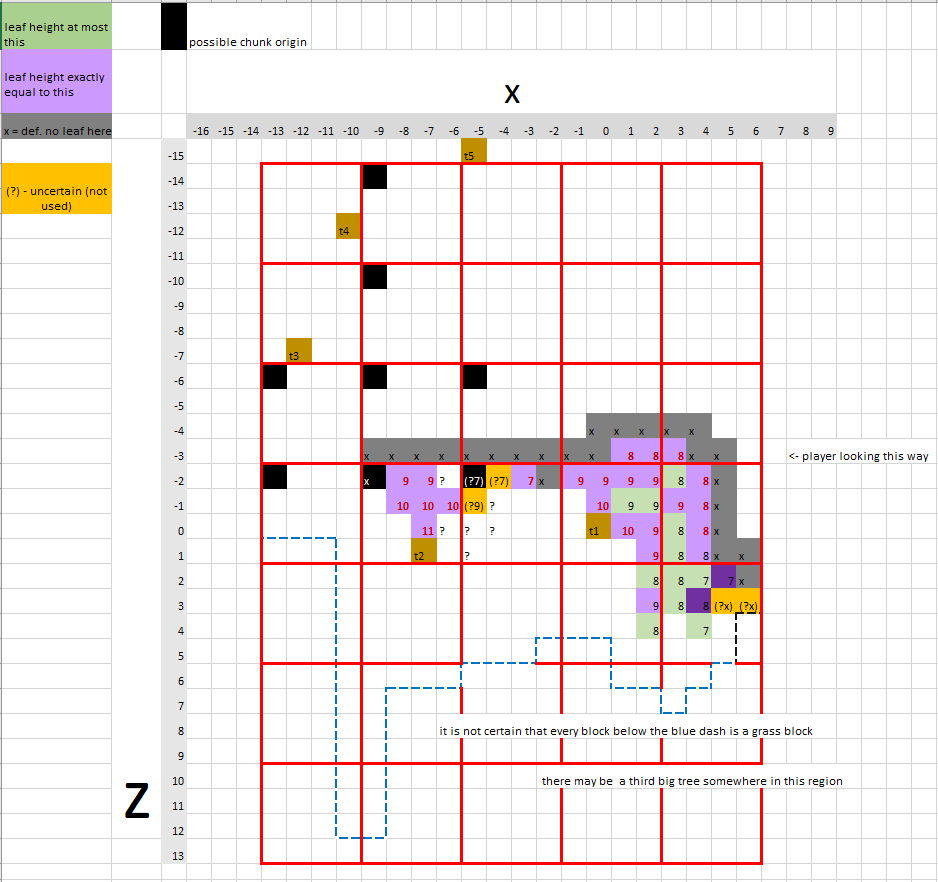
Note that this table had a crucial error (discussed later): the y-value at (4,1) should be 7, not 8
Methodology Part 1: GPU Stage
Big trees are generated in the chunk population stage. We call the internal state of the Java Rand just before it starts tree generation the “tree seed”.
There are several nice things about big trees with regards to seed cracking:
- Only 1 in 10 chunks is a big tree chunk, decided using a simple Random.nextInt(10)==0 check at the beginning of tree generation.
- Unlike for small trees, there is no variability in the number of calls to rand per big tree placement attempt. This lack of branching simplifies things.
- The “tree size” of a big tree is also the same for every big tree in the same chunk. It is a random value ranging from 5 to 16. Its value is decided using an expression like TreeSize = Random.nextInt(12) + 5.
- Just like for small trees, the position of each tree placement attempt within the chunk is decided using chunkX = Random.nextInt(16); chunkZ = Random.nextInt(16). There are 256 possible locations within a chunk for each attempt.
It is unclear if the two big trees are in a single chunk or two separate chunks. There was some suggestion that they were in the same chunk based on fog analysis. However, the odds of two chunks both being big tree chunks with the same big tree size is 1 in 120, making the two big trees being in one chunk seem like the initially more likely option.
In addition, having two trees gives substantially fewer candidate seeds for further (leaf) filtering, which makes it a lot easier to check first. The difference in difficulty is demonstrated by the crude comparison below.[4]
Two trees:
N = 2^48 / 10 / 12 / (256^2) = 35.8 million
But, there is x2 factor (you don’t know which tree placed first)
N = 71.6 million (~22 bits of filtering)
And a x6 factor (six possible chunk offsets)
Yielding 430 million candidates
One tree:
N = 2^48 / 10 / 12 / 256 = 9.16 billion (~15 bits of filtering)
There is a x2 factor (two possible chunk offsets)
Yielding 18.3 billion candidates
Note that there are over twenty times as many seeds left over after this stage of filtering. For this reason (and the probabilistic argument above) the case of the two big trees being in separate chunks was ignored until recently (around the New Year).
Both of the above are still underestimates (perhaps by a factor of 2-5), because of a combinatorial factor to account for the distinct possibility that more than 2 tree attempts could have occurred when the two trees were placed, and it could have been any two of these attempts which placed the two trees we see. If there were at most N tree placements, there would be N(N-1)/2 ways to choose which two were the successful placements. N = 7 would be a very safe upper bound for the number of tree attempts. This would give a multiplier of 21. Why then does accounting for this only result in a factor of 2-5 increase in how many possible seeds we get? Most candidates where a large number of tree placements occurred can be eliminated using the knowledge that there are no trees except the two we see over a fairly large proportion of the big tree chunk (although for some chunk alignments less of the relevant chunk is visible). If we ever get a tree placement attempt in a “forbidden” location which certainly would have succeeded[5], and resulted in a tree being placed which we don’t see, then we know that this seed is wrong and can be eliminated. When a large number of tree attempts are made, there are a large number of chances for something to go wrong, so actually most of the candidate seeds have 2 or 3 tree attempts.[6] See the table of the actual number of candidates for each offset in the appendix.
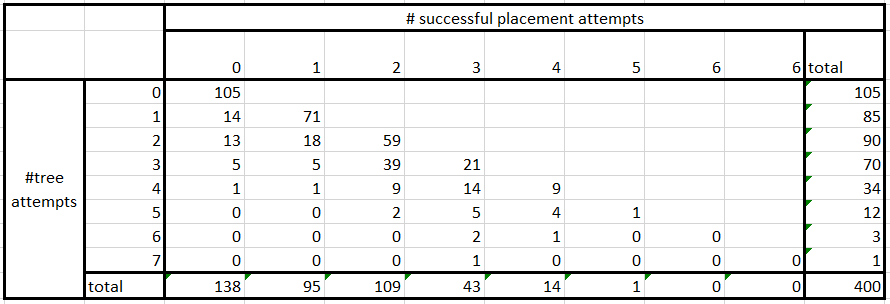
The table above gives some statistical evidence for this claim. Looking at the “2” column we see that if we observe 2 successful big tree placements, then there is approximately a 59/109 probability that there were only 2 actual tree placement attempts, and a 39/109 probability that there were 3 tree attempts. There is only a pretty small (11/109) chance that there were 4 or more tree attempts. This is partly because it is increasingly rare for large numbers of tree attempts to be made, but also because it is very likely that when you make a large number of tree attempts, you will get a fairly large number of successful tree attempts.
Methodology Part 2: CPU Stage, the big tree leaf filter
There are billions of different shapes a big tree can take, and we have the good fortune of having a fairly good view of two big trees in the Herobrine screenshot. It might be the case that a particular big tree is only generated by a single big tree seed, so if you find that seed, it is a fairly routine process to find the world seed (by guessing the coordinates and converting the chunk seed to a world seed). It would probably be an overstatement to say that every big tree is unique, but it would be fair to say that the closer big tree we see in the Herobrine screenshot is one in a billion.
This would be a very neat and moderately simple way to filter down the billions of candidates from the GPU stage down to the one and only correct seed. Matters are complicated, however, by the fact that the Herobrine screenshot is from minecraft alpha 1.0.16_2, and a feature of the game at this time was the “leaf decay bug” where seemingly any leaf had a chance to decay at any time (for seemingly no reason). This means the trees in the screenshot do not have all the leaves they had when they were generated. Leaves decay with a lot of randomness which does not depend on the seed - if you regenerate the same world the leaves are very likely to decay in a different way. Leaf decay is sort of like an entropy which gives you negative bits of information.
The basic and sure-fire approach would be to check that every leaf which we observe in the screenshot is generated by a candidate seed. This works because while a leaf block can change into an air block through leaf decay, an air block certainly cannot change into a leaf block. This method results in quite a weak filter; we would lose a great deal of information by completely ignoring absences of leaf blocks.
Luckily, even broken leaf decay is not entirely random, and not every leaf has an equal chance of decaying. The table below shows the results of looking at every leaf-decay event for a sample of 100,000 size 11 big trees. The type of block vertically above and below the leaf which decayed was checked, and separately, whether the leaf was horizontally adjacent to a log.
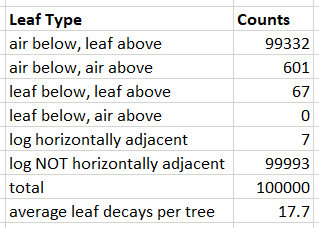
The table above shows that leaves have a very strong tendency to decay “from the bottom up”. It is particularly interesting that zero events where a leaf block with an air block above it and a leaf block below it decayed were observed. It is also extremely rare for a leaf block to decay when it is next to a log. While it isn’t impossible that either of these two events occurred in the Herobrine trees, it is extremely useful to assume that they didn’t. This is because this allows us to check for the presence of a large number of air blocks which must not have a leaf when the trees were generated. A way of rephrasing the absence of “leaf-below, air above decays” is to say that all the air blocks above the trees’ canopy must also have been air blocks when the tree was generated. The “leaves almost-never decay next to logs” observation can be rephrased as all the air blocks we see around the trunks of the two big trees must also have been air blocks when the big trees were generated.
Leaves which are on the underside of the big trees are mostly useless, as we don’t know if there was a leaf underneath them when the trees were generated. The tentative branch placements in the tree turn out to also be of little use (especially as they are not 100% certain) - it turns out that the arrangement of the leaves indirectly tells you where the branch blocks will be to a fairly high certainty.
On the other hand, the leaf at (0, 3, 1) and lack of leaves at (0, 3, -1), (1, 3, 0) and (-1, 3, 0) next to a log are pretty useful. Only two leaves which don’t have air above them, or a log block next to them, are used in the filter. These are the leaves at (0, 5, -2) and (-1, 5, -2). These leaves are unambiguous, and it is somewhat unusual to have leaves in that position on a big tree.
Coordinate dependence
An important feature of big tree generation is that the same tree seed can result in different trees based on the coordinates. This is pretty unintuitive and unlike small tree generation. There appear to be nine different possibilities based on the sign of the x and z coordinates (positive, negative, or zero for each - so 3x3 = 9) [7]. It is much more likely neither x nor z are zero than one of them are (which is 2x2 = 4 cases).[8]
Implementation
The CPU tester for this stage is written in Java. It contains a copy/paste of the WorldGenBifTree source code from decompiled Minecraft alpha 1.1.2. Each thread can check about 5,000 seeds per second. Thus, 8 threads can check about 40,000 seeds per second. A billion seeds could be checked in under 7 hours at this rate. It would take a lot of effort and care to convert all this code to gpu/C code, but in that case the runtime could be negligible (minutes?). This was not done because it would probably be an error-prone and time-consuming feat (“Could I have made a mistake translating hundreds of lines of Java to C?”), and because the initial GPU filter takes many hours to run anyway it wouldn’t actually save much time.
Results
The result was successful! See update on next page
At present all the code has been written and run (much of it in late September, with some more in December and early January). Using all the leaf data that seems reliable, it is very unfortunate that every single candidate outputted by the gpu filter is eliminated, resulting in zero matches. While tests are ongoing, it is unclear why the method has failed.
What to do next?
Test and debug leaf filter, revisit all the assumptions made. Make sure all the data used is correct.[9]
Mabe run a brute-force terrain-only checker over all chunk coordinates which either contain x=0 or z=0 as this case has not been fully exhausted using the tree check for the case of the two big trees being in separate chunks..
Terrain-only checker for all coordinates using Neil’s code (for boinc)
Update:
15/01/2021
~16:00
Could it have been a wrong leaf all along?[10]
There seem to be some pixels wrong. Can rerun on intermediate results within 10 minutes.
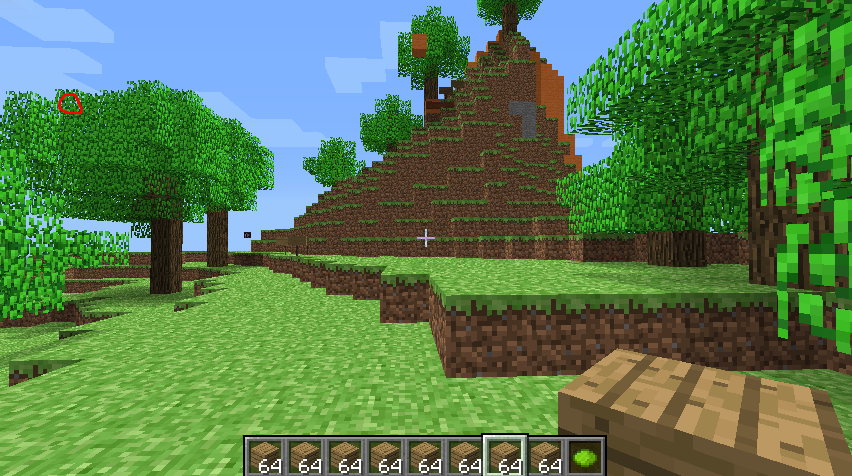
The red circle shows where the wrong leaf is located


Original : the are some white pixels here Error in recreation: the white pixels have been
filled by a leaf which shouldn’t be there
~ 16:22
Re-analysis complete.
11 candidate tree seeds found
Manual inspection eliminates 10 of the 11 candidates. Leaving only 1 candidate tree seed.
Now run the chunk-to-world seed program on this tree-seed. Try all chunks within 64 chunks (1024 blocks) of (0,0) and cross-reference with the nearby small trees.
~ 00:21 success !!! world seed found.
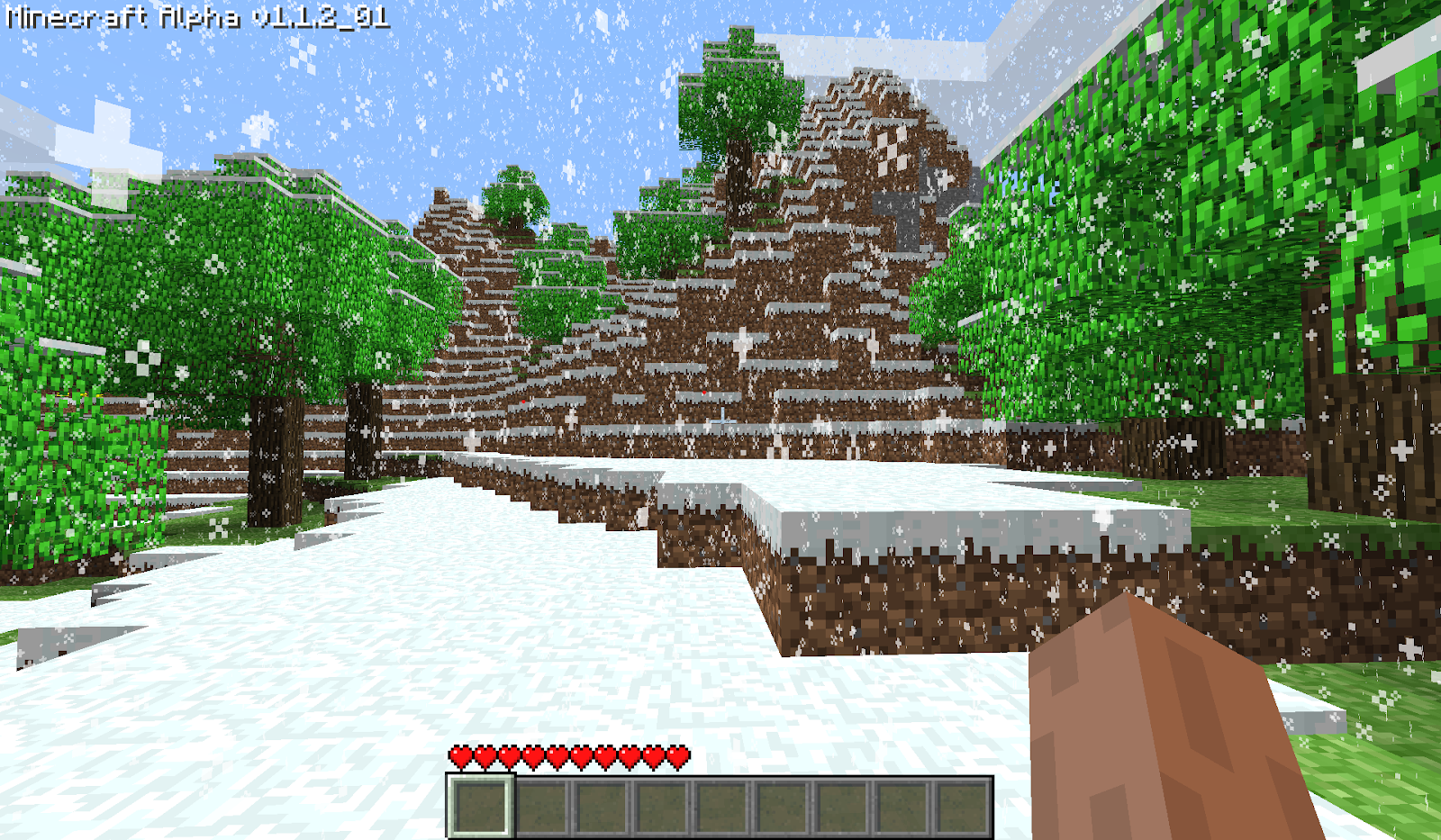
“Herobrine but the fog has lifted and the snow has fallen”
Resources
Code:
https://github.com/andrew5555555/herobrine
Discussion:
Credits sheet:
https://mcatho.me/herobrinecredits
Live recreation overlay:
https://codepen.io/Tomlacko/full/PoNENLJ
Appendix 1
Probably it is worth giving how many candidate tree seeds the GPU and CPU filter gave for each alignment
T1 chunk alignment | GPU filtered (using big tree positions) | CPU filtered (using leaves) | Manual filter |
(9,2) | 401,757,490 | 4 | 0 |
(9,6) | 300,747,690 | 2 | 0 |
(9,10) | 198,236,108 | 2 | 1 |
(9, 14) | 152,657,082 | 0 | 0 |
(13, 2) | 292,937,019 | 1 | 0 |
(13, 6) | 280,063,856 | 2 | 0 |
(5, 2) | 14,316,506,886 | Not tested with corrected leaf data | - |
(5, 6) | 15,927,157,682 | Not tested with corrected leaf data | - |
Note how the offsets with the two big trees in separate chunks have way more candidates (as we can only use one tree to filter the candidates. These were not tested with the corrected leaf data because it was not necessary, and they are much larger (by a factor over 20)![11]
Appendix 2
Motivation for inspecting the leaf that was wrong.
The few pixels of discrepancy between the original jpeg and the recreation were very subtle and hard to spot. This is why the mistake had gone undetected for many months despite checks and validations by many people who worked on the problem.
It was not a lucky guess that the leaf was wrong but rather the result of months of debugging which suggested that there was something wrong on the left side of the big tree. Specifically, it was found that if there is a leaf at (4,8,1), there must be leaves at (5,7,0) and (5,7,1). These two leaves are clearly absent in the screenshot, so the initial conclusion (assuming that all the data was correct) was that a very rare type of leaf decay must have occurred on these leaves to make them disappear.
To give an idea of how rare such a decay would be, the leaf at (5,7,1) was observed to decay only 3 times out of many thousands, while the leaf at (5,7,0) was never observed to decay. After several months of testing, the confidence in my code and assumptions became greater than my confidence in the data, which is why I tried to find a justification for the leaf at (4,8,1) being wrong.
After finding evidence that the leaf at (4,8,1) was indeed not actually there by closely examining the original image, this leaf was discarded from the filter, and the world seed was found several hours later.
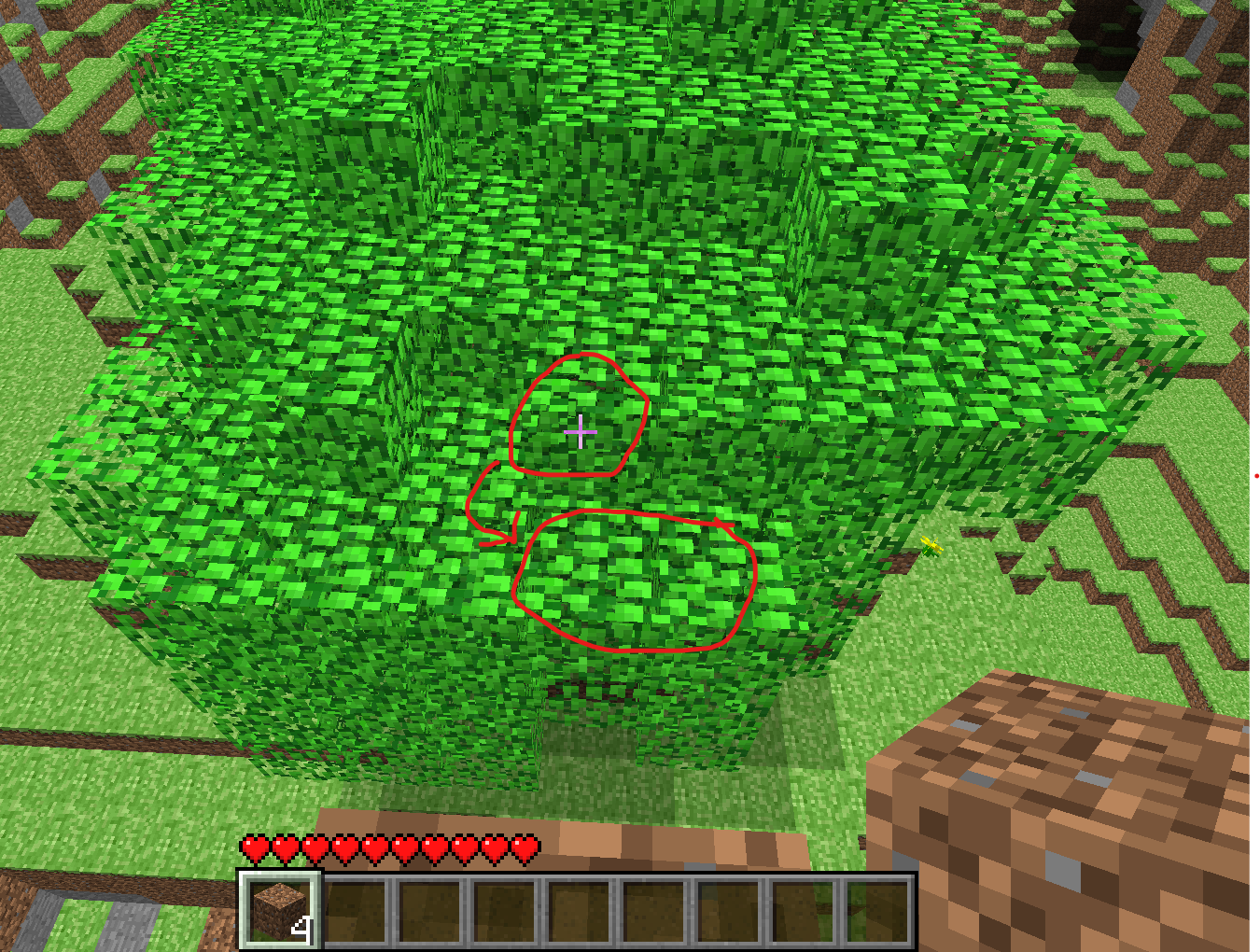
Image: presence of the (4,8,1) leaf forces the presence of the (5,7,1) and (5,7,0) leaves which shouldn’t be there and are highly unlikely to decay.
[1] By “tree size” I mean the value of “field_878_e” in WorldGenBigTree (minecraft alpha 1.1.2). The actual version of minecraft in the original screenshot was 1.0.16, but it seems that as far as trees are concerned there is no difference between these versions. This is exactly equal to the height of the highest leaf in the big tree relative to the dirt block on which the tree spawned.
[2] Should talk to Pseudogravity about this
[3] A big tree cannot naturally spawn in a location where there are leaves above the ground.
[4] N.B. There is a negligible difference in the GPU time required for a 1-tree or a 2-tree filter (it is approximately 10 hours per chunk offset either way on an RTX 2070 Super). For the 2-tree case, the time required by the CPU leaf-filter (4-core, 8 threads) is somewhat less than 10 hours, so the cpu checks can run in parallel with the gpu filter. For the 1-tree case the cpu checks take about 20 times as long as the gpu filter (i.e. weeks of cpu-time). They were completed in a few days by splitting them over 5 separate computers (4-6 cores each).
[5] Big tree attempts (unlike small tree attempts) always succeed provided that the highest block at their x/z coordinates is either grass or dirt. (except for the very special case when they are cut off by the height limit of y=128, which is certainly not the case here)
[6] Weird things (like unseen holes in the ground) can cause this filtration step to make false negatives (which would be very bad if one of those false negatives is the correct seed). Apart from this, there is no doubt that all the methodology and code up to this point is correct.
[7] Presumably this is due to the fact that floating point math is used to generate big trees, with floating point numbers eventually being converted to integer block coordinates. This is due to the peculiarity of java int casting of rounding positive floating point numbers down and negative numbers up, that is, rounding towards zero. The result of this is that some (but not all) of the leaves on a big tree are shifted around relative to the trunk as you move from quadrant to quadrant. The literal “edge case” part of the tree being in a positive quadrant and part of the tree being in a negative quadrant causes half of the leaves to be shifted one way and half to be shifted the other way.
For example:
int a = (int) +4.9; // a is now 4, rounded down
int b = (int) -4.9; // b is now - 4, rounded up
int c = (int) +3.14; // a is now 3, rounded down
int d = (int) -3.14; // b is now - 3, rounded up
[8] While all nine possibilities were checked for the 2-tree case, only the 4 “likely” options of non-zero possibilities were checked for the 1-tree case due to lack of computer power. There is a very small chance that the Herobrine seed happens to lie in such a category.
[9] Wrong data was indeed the problem. All code was already correct in late September.
[10] See appendix 2 for what the motivation for thinking that this leaf was wrong were.
[11] All GPU candidates, including the split tree case, had earlier been tested with the wrong leaf data, which gave zero matches.